Overview
In a previous article titled Inspector or: How I Learned to Stop Worrying and Love Testing in Prod, we discussed our end-to-end testing solution, Inspector, which we leverage to perform continuous testing of our external attack surface enumeration scanning system. Here, we discuss some of the recent modifications and updates we made to Inspector to improve overall performance and scalability and reflect on some of the issues we identified with our initial implementation.
Problem #1: Performance Issues with Snapshotting Method
The first issue we encountered with the previous implementation related to the snapshotting method that captures events during the end-to-end testing period. This is because the previous solution determined which events were part of the end-to-end tests by snapshotting the state of all topics and partitions within the Kafka pipeline and then inspecting all new events that appeared during the testing window. Unfortunately, this was quite slow as it meant the Inspector container job would need to access and inspect every event created within the testing window.
The main advantage of this approach is that it was entirely agnostic of the underlying service. This was a requirement as part of the initial implementation of Inspector, because at that time we didn’t have a standardized framework for services to create or process events from Kafka. This meant that disparate services might use one of multiple different methods–including a sidecar, direct kafka interaction, or Benthos–for either consuming or producing events to a topic.
Fortunately, one of our recent initiatives involved migrating all our core services within the scanning pipeline to the Benthos stream processing framework. This framework allows for flexible configuration of how events are processed, and includes the ability to layer disparate event processors together to allow for the flexible configuration of individual scanning services. Migrating to a standardized event streaming framework allowed us to improve our ability to aggregate information on end-to-end test events.
Solution: Building a Custom Benthos Processor
To address the performance issues associated with snapshotting the entire pipeline we implemented a new architecture which leveraged a custom Benthos processor. Its role is to inspect any events produced by a service and log them to a topic named “caseInspectorEvents” whenever it determines that the event is associated with an end-to-end test.
We accomplished this by adding a new field named “metadata“ to our event header. “Metadata“ allows for events to contain arbitrary pairs of metadata. The general convention in this case is that input events should always propagate the metadata associated with the input event to the output event generated by the service. Figure 1 shows an example of an event with a “test” field in the metadata header indicating the event is part of an end-to-end test.
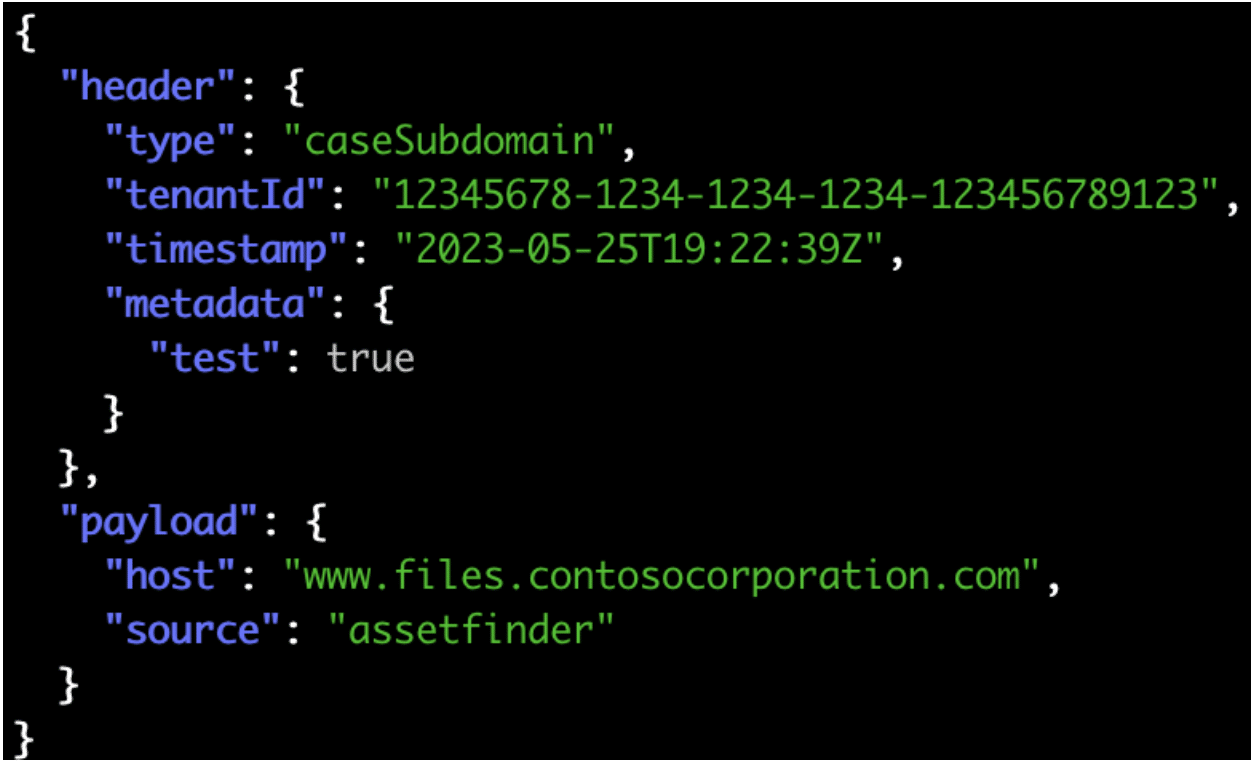
Figure 1: A simplified event created as part of an end-to-end test with the relevant metadata header field present in the event header.
Next, we developed a custom Benthos processor called “case_tester” that simply inspects the metadata event field in the event header to determine if an event is a part of an end-to-end test. If the event is part of an end-to-end test, the processor will write the event to the caseInspectorEvents topic. Figure 2 shows the output section of an example Benthos configuration using the case_tester processor to inspect all events the service generates.
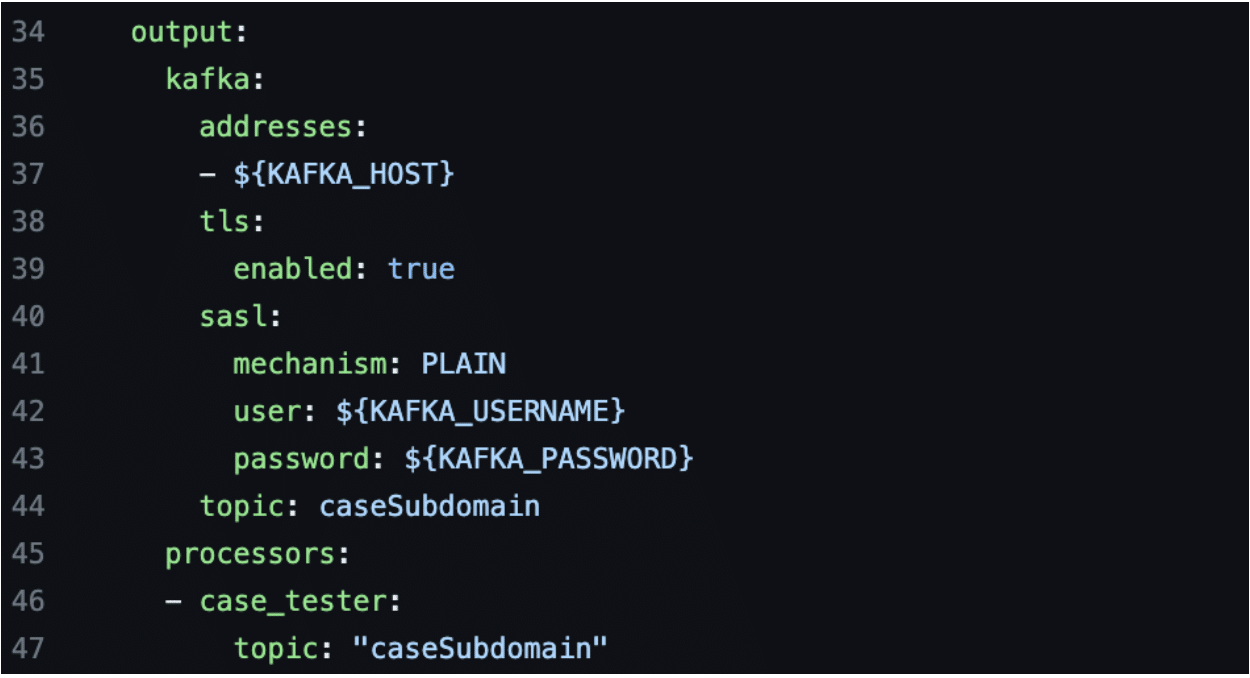
Figure 2: An example Benthos configuration leveraging the case_tester processor to monitor for events produced by a service as being associated with an end-to-end test.
In this case, the Inspector service simply reads the new events written to the caseInspectorEvents topic without needing to snapshot the entire pipeline and examine every event created since initiation of the previous end-to-end test.
The addition of a metadata field to the event header during this initiative was also valuable as it adds options for additional extensibility in the future in terms of being able to add metadata annotations to events. For example, we may need to flag an event as being part of a certain type of scan. This could be useful if we are leveraging the Chariot scanning pipeline during a red team engagement and would like to handle these types of scans leveraging more of a low-and-slow approach. This would contrast with our traditional scanning mechanism, which isn’t as focused on stealth or evasion.
Problem #2: Coverage of Databases and APIs
The other problem we identified fairly quickly was that while our tests included coverage of the events within kafka itself, it didn’t include coverage of many of the databases and application programming interfaces (APIs) that render information in the frontend. In some instances, we identified problems where the underlying persister service failed to persist data to the database even though the appropriate events existed within the Kafka topic.
To solve this problem, we implemented checks which invoke various backend microservices to verify that the discovered assets and vulnerabilities are persisted and returned properly. This change now allows us to have full visibility of the entire end-to-end scanning process.
Conclusion
In this article, we discussed some of the adjustments we’ve recently made to our end-to-end testing capabilities to improve the reliability and performance of our scanning pipeline. The ability to perform continuous end-to-end testing is a critically important capability to support development team velocity while still ensuring the reliability and stability of the scanning pipeline.
